THUCTC工具包
 潇潇
潇潇数据集内容:文本分类任务的目的,是想办法预测出文本对应的类别,是NLP的基础任务。
比如对新闻分类:政治、体育、军事、社会,微博评论分类:好评、中评、差评。
文本分类的过程,通常包括特征选取、特征降维、分类模型学习三个步骤。如何选取合适的文本特征并进行降维,是中文文本分类的挑战性问题。
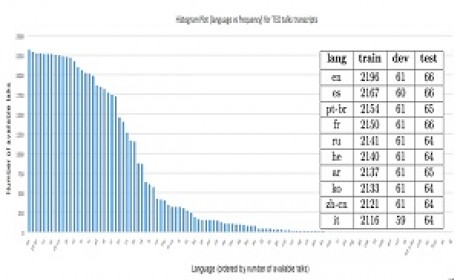
THUCTC(THU Chinese Text Classification)是由清华大学自然语言处理实验室,推出的中文文本分类工具包,能够自动高效地实现用户自定义的文本分类语料的训练、评测、分类功能。
数据集功能:中文文本分类
下载链接:http://thuctc.thunlp.org/
彩蛋1:
算法工程师开发重磅福利:
(1)算法工程师模型部署利器,算法开发平台,安卓手机即可使用,点击查看体验。
(2)智慧安防、智慧交通、智慧社区实战训练营,点击加入。
彩蛋2:
大白购买了不少数据集,以及不断整理各种类型的数据集,放到百度网盘中,便于大家下载使用。
数据集列表及下载方式:点击查看
彩蛋3:
《AI未来星球》陪伴成长的人工智能社群,价值过万的各种内部资源及活动,限时特惠中,点击查看。